
.png)

-bpoi.png)
Hermes 接入 XCrawl Skill:一键搞定批量网页抓取与 RAG 知识库搭建
来源
正文
作者:未来奇点
痛点:Hermes 无法高效处理大批量网页
使用 Hermes 时,查询单个网页没有问题。但一旦需要批量搜索、页面数量增多,速度便会明显下降,弹窗等干扰也无法自动处理。这是 Hermes 一直以来的短板。
解决方案:神级 Skill —— XCrawl
通过一键接入 XCrawl Skill,上述问题迎刃而解。该 Skill 专为大规模网页数据采集设计,填补了 Hermes 在批量抓取方面的不足。
重点是目前可以白嫖积分,无需额外付费。
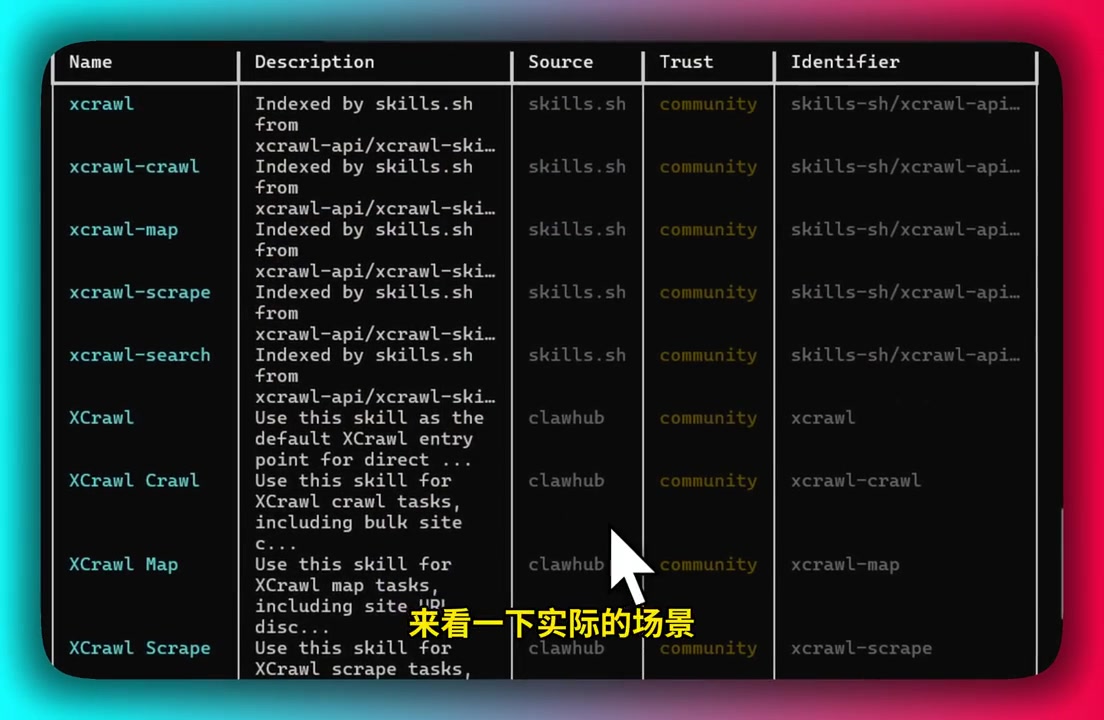
Hermes 接入 XCrawl Skill 后的演示界面
实战场景一:快速搜集产品评价
例如想了解某款热门设备(如耳机)的真实用户评价。让 Hermes 直接搜索评测和反馈,它会通过 XCrawl 内置的 search 方法查找公开网页(社交媒体帖子、新闻评测等),再用 Scrape 功能将重点页面提取为干净的 Markdown 和 JSON 格式,最后自动整理成一份消费决策报告。
报告中会清晰列出佩戴舒适度、漏音情况、续航等维度的表现,总结一目了然。
实战场景二:搭建自己的 RAG 知识库
如果需要大量文档数据来构建 RAG 知识库,例如将一个公开的文档站(包含快速开始、API 参数、错误码、示例代码、常见问题等,少则几十页多则上百页)转化为结构化数据,手动整理极其繁琐。
使用 XCrawl Skill 后流程变得清晰:
- 先用
sitemap扫描站点,获取所有 URL; - 筛选出真正有用的文档页面;
- 用
crawl 或batch scrape把内容统一提取为 Markdown; - 最终整理出标题、原始链接、章节内容、摘要、关键词和 FAQ。
这样处理后的完整数据可以直接存入向量数据库,变为一个支持问答的 RAG 知识库。
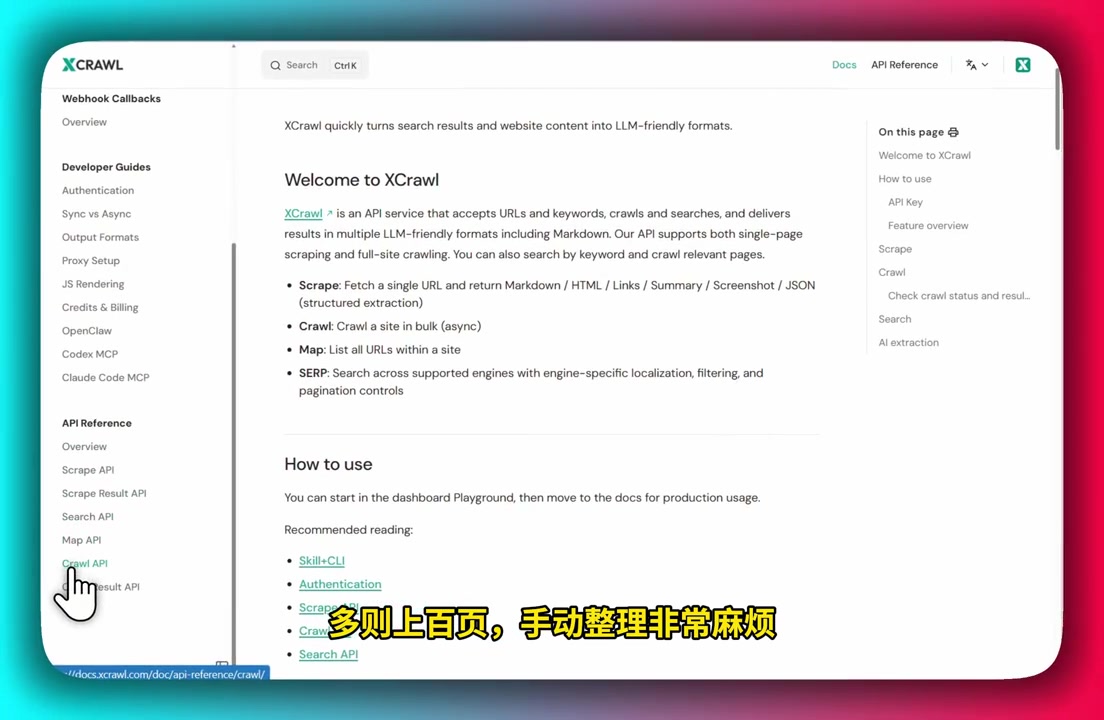
XCrawl Skill 处理文档站并生成结构化数据的过程
使用体验与核心优势
XCrawl Skill 最大的特点是 稳定,成功率至少 90% 以上。这得益于其内置的高质量住宅代理池和智能指纹策略,用户无需自己维护服务器和采集环境。只要有公开网页,它基本都能获取到数据。
官方还赠送了 1000 积分,足够用一段时间,非常省心。
逐字稿
00:00 最近发现了一个神级Scraper
00:01 刚好补上Hermes的最大短板
00:03 它不能抓取大规模的网页数据
00:05 你在用Hermes的时候
00:07 一定遇到过这种情况
00:08 让它查一个网页没问题
00:09 但是只要任务变成批量搜索
00:11 页面一多
00:12 速度变慢
00:12 而且弹窗的问题
00:13 它都没办法处理
00:14 但是你看我一键配置了这个Scraper后
00:16 完美解决了这个问题
00:18 重点是
00:18 能白嫖
00:19 来看一下实际的场景
00:20 最近刚好想看看某个很火的
00:22 我家这个机
00:23 的真实评价
00:24 直接去让它搜索评测和反馈
00:26 它可以调用XCral中的search方法
00:28 找公开网页
00:29 比如社交媒体的帖子
00:31 以及新闻评测
00:32 再用Scribe
00:33 把重点页面提取成干净的
00:35 Markdown和Json
00:36 然后自动整理成一份消费决策报告
00:38 你看看像佩戴舒适度
00:39 漏音
00:40 续航等等表现
00:41 分别怎么样
00:42 总结下来一目了然
00:43 非常全面
00:44 如果你还想要搭建自己的RAG知识库
00:46 就要用到大量数据
00:47 比如我想把一个公开的文档站
00:49 整理成知识库
00:50 如果只靠Agent自己读取网页
00:52 Token不够不说
00:53 它可能只能处理几个页面
00:55 页面一多就很难保证完整些
00:56 但一个文档站
00:57 通常有快速开始
00:59 API参数
00:59 错误码
01:00 示例代码
01:01 场景问题等等
01:02 少则几十页
01:02 多则上百页
01:03 手动整理非常麻烦
01:05 用了XRawSkill后
01:06 流程就清楚多了
01:07 它可以先用Map扫出站点里的URL
01:09 再筛选出真正有用的文档页面
01:11 接着用Crawl或Puppeteer Scrape
01:13 把内容统一成Markdown
01:14 最后整理成标题
01:15 原始链接
01:16 章节内容
01:17 摘要
01:17 关键词和FAQ
01:18 这样处理的完整数据
01:19 就可以直接进向量数据库
01:21 变成一个能问答的RAG支持库
01:23 这个XRawSkill
01:23 我用下来最大的感受就是稳定
01:25 成功率最起码百分之90以上
01:26 主要是内置了高质量住宅代理池
01:29 和智能指纹策略
01:30 不用自己维护服务器和采集环境
01:32 而且用起来相对来说
01:33 功能强大得多
01:34 只要是公开网页都能获取到数据
01:36 而且重点来了
01:37 XRawSkill官网送1000积分
01:38 能白嫖就赶紧白嫖
01:39 目前用下来感觉非常省
01:41 这些积分够用一段时间
内容效果不满意?点此反馈




